Triage - A Kafka Proxy
Introduction
Triage is an open-source consumer proxy for Apache Kafka that solves head-of-line blocking (HoLB) caused by poison pill messages and non-uniform consumer latency. Once deployed, poison pill messages will be identified and delivered to a dead letter store. By enabling additional consumer instances to consume messages, Triage uses parallelism to ensure that an unusually slow message will not block the queue.
Our goal was to create a service that could deal with HoLB in a message queue while making it easy for consumer application developers to maintain their existing workflow.
This case study will begin by exploring the larger context of microservices and the role of message queues in facilitating event-driven architectures. It will also describe some of the basics regarding Kafka’s functionality and how HoLB can affect consumers, followed by an overview of existing solutions. Finally, we will dive into the architecture of Triage, discuss important technical decisions we made, and outline the key challenges we faced during the process.
Problem Domain Setup
The World of Microservices
Over the last decade, microservices have become a popular architectural choice for building applications. By one estimate from 2020, 63% of enterprises have adopted microservices, and many are satisfied with the tradeoffs [1]. Decoupling services often leads to faster development time since work on different services can be done in parallel. Additionally, many companies benefit from the ability to independently scale individual components of their architecture, and this same decoupling makes it easier to isolate failures in a system.
Microservice architectures are flexible enough to allow different technologies and languages to communicate within the same system, creating a polyglot environment. This flexibility enables a multitude of different approaches for achieving reliable intra-system communication.
Two common options are the request-response pattern and event-driven architecture (EDA). Although the latter is where our focus lies, it is useful to have some context on the shift toward EDAs.
From Request-Response to Event-Driven Architecture
A typical request-response pattern is commonly used on the web, and that is no different from what we are referring to here. For example, imagine a number of interconnected microservices. One of them sends a request to another and waits for a response. If any one of the services in this chain experiences lag or failure, slowdowns cascade throughout the entire system.
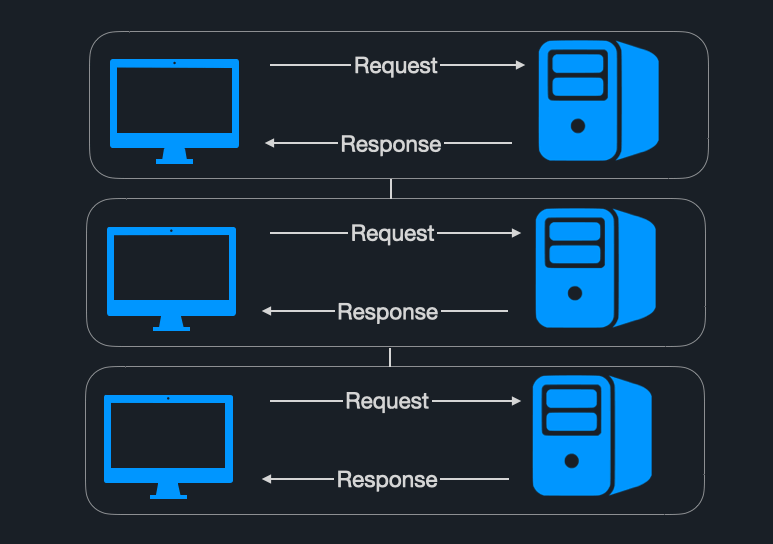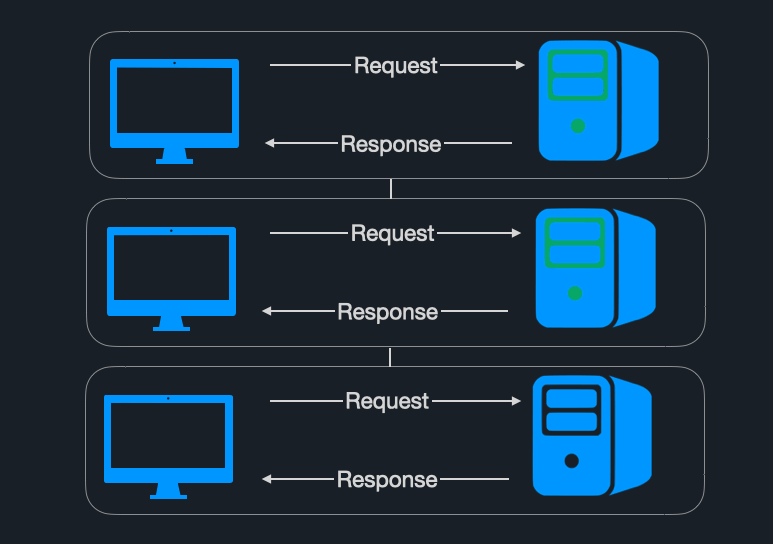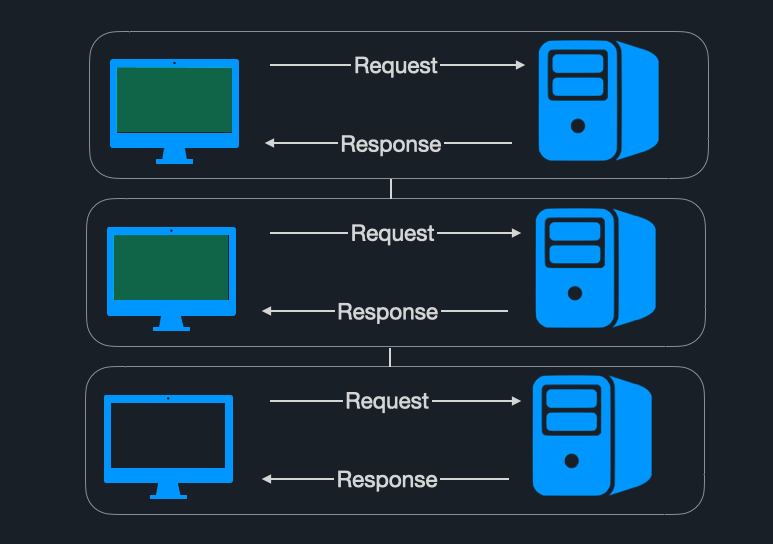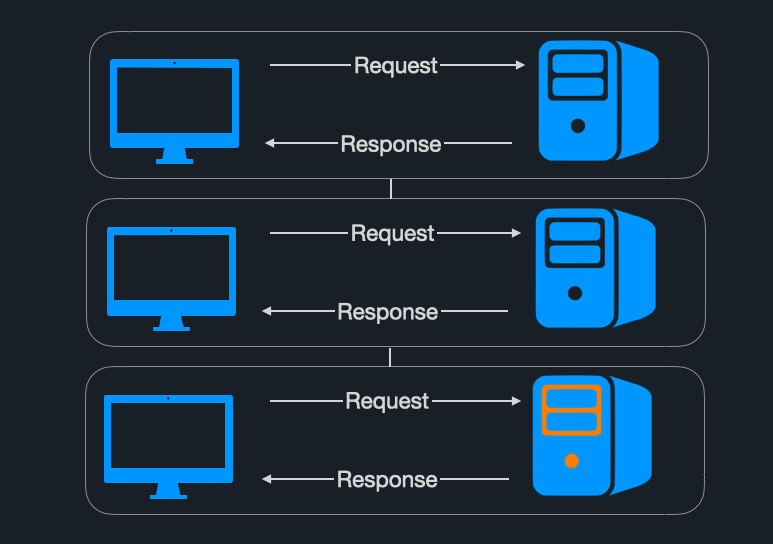
In an EDA, however, the approach is centered around “events”, which can be thought of as any changes in state or notifications about a change. The key advantage is that each service can operate without concern for the state of any other service - they perform their tasks without interacting with other services in the architecture. EDAs are often implemented using message queues. Producers write events to the message queue, and consumers read events off of it. For example, imagine an online store - a producer application might detect that an order has been submitted and write an “order” event to the queue. A consumer application could then see that order, dequeue it, and process it accordingly.
Apache Kafka
What is Kafka?
In a traditional message queue, events are read and then removed from the queue. An alternative approach is to use log-based message queues, which persist events to a log. Among log-based message queues, Kafka is the most popular – over 80% of Fortune 100 companies use Kafka as part of their architecture [2]. Kafka is designed for parallelism and scalability and maintains the intended decoupling of an EDA. In Kafka, events are called messages.
How Does Kafka Work?
Typically, when talking about Kafka, we are referring to a Kafka cluster - a cluster is comprised of several servers, referred to as brokers, working in conjunction. A broker receives messages from producers, persists them, and makes them available to consumers.
Topics are named identifiers used to group messages together. Topics, in turn, are broken down into partitions. To provide scalability, each partition of a given topic can be hosted on a different broker. This means that a single topic can be scaled horizontally across multiple brokers to provide performance beyond the ability of a single broker. Each instance of a consumer application can then read from a partition, allowing for parallel processing of messages within a topic.

Consumers are organized into consumer groups under a common group ID to enable Kafka’s internal load balancing. It is important to note that while a consumer instance can consume from more than one partition, a partition can only be consumed by a single consumer instance. If the number of instances is higher than the number of available partitions, some instances will remain inactive.
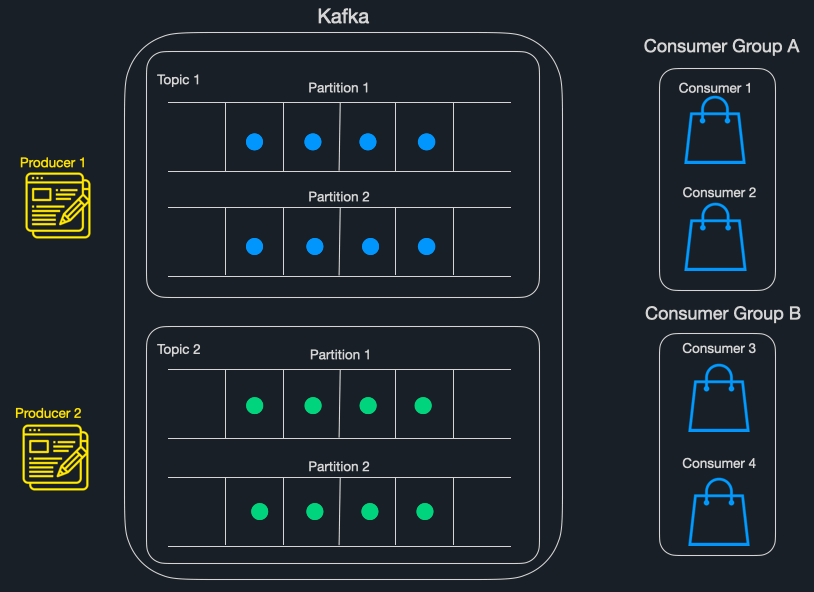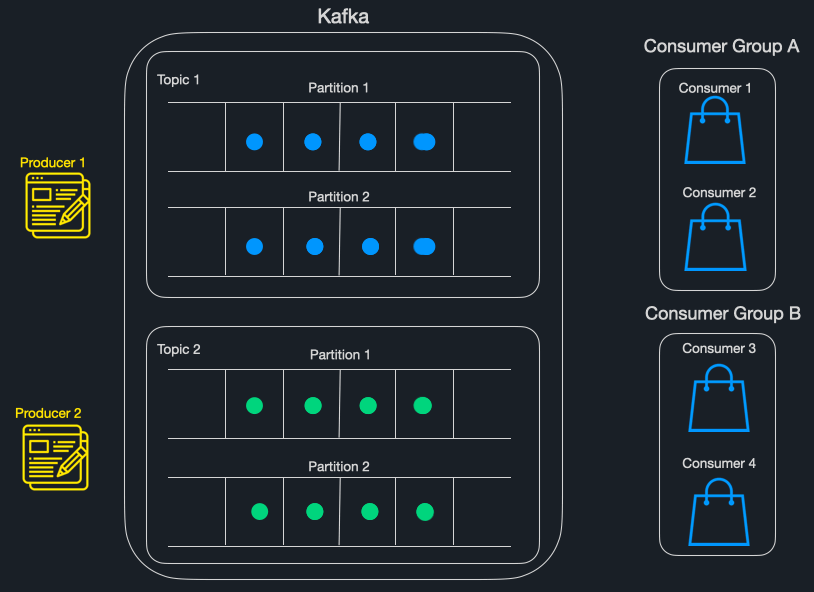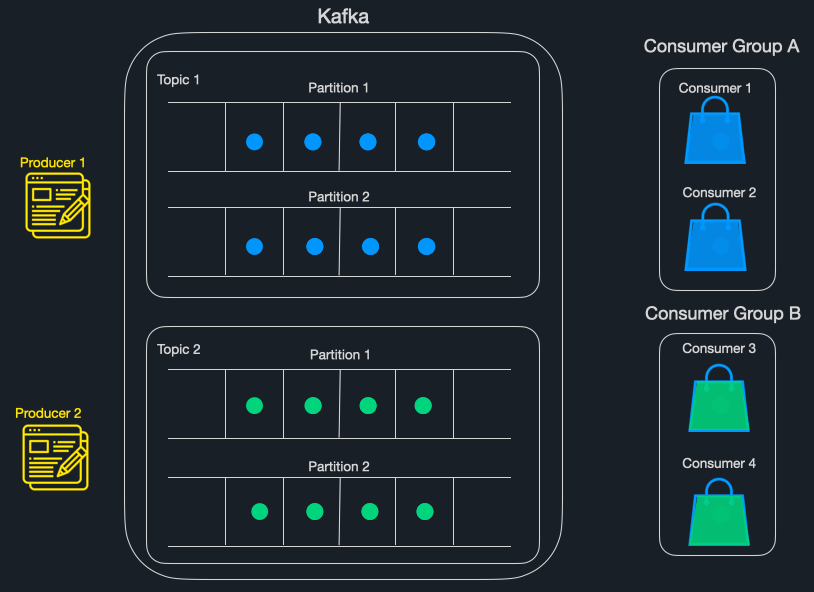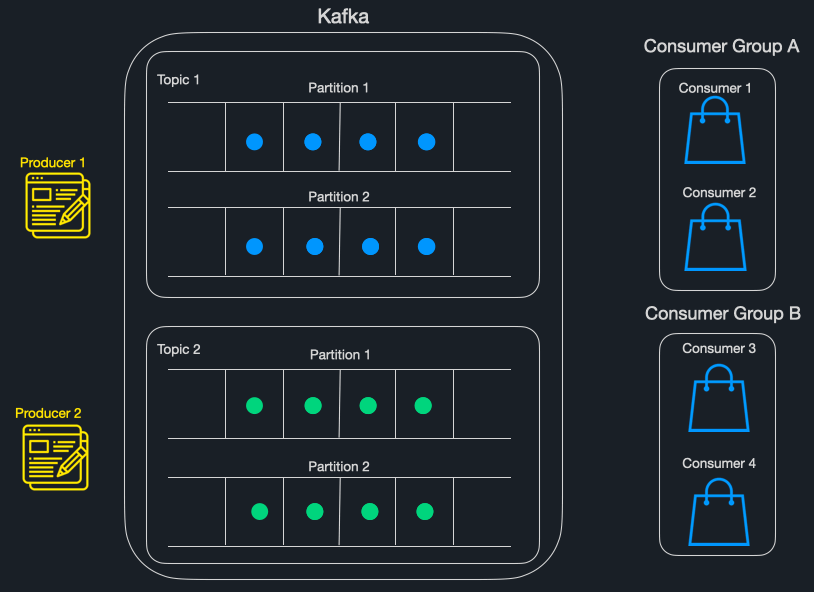
Internally, Kafka uses a mechanism called “commits” to track the successful processing of messages. Consumer applications periodically send commits back to the Kafka cluster, indicating the last message they’ve successfully processed. Should a consumer instance go down, Kafka will have a checkpoint to resume message delivery from.
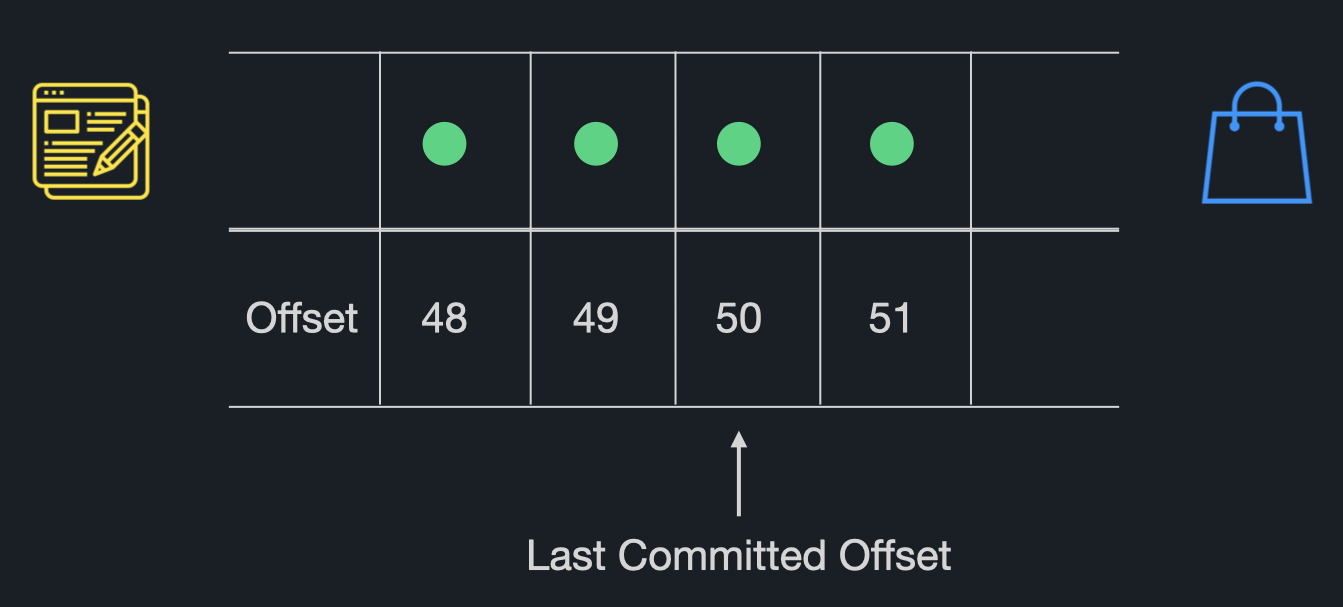
Problem Description
Head-of-Line Blocking in Kafka
A significant problem that can be experienced when using message queues is head-of-line blocking (HoLB). HoLB occurs when a message at the head of the queue blocks the messages behind it. Since Kafka’s partitions are essentially queues, messages may block the line for two common reasons – poison pills and unusually slow messages.
Poison Pills
Poison pills are messages that a consumer application receives but cannot process. Messages can become poison pills for a host of reasons, such as corrupted or malformed data.
HoLB Due to Poison Pills
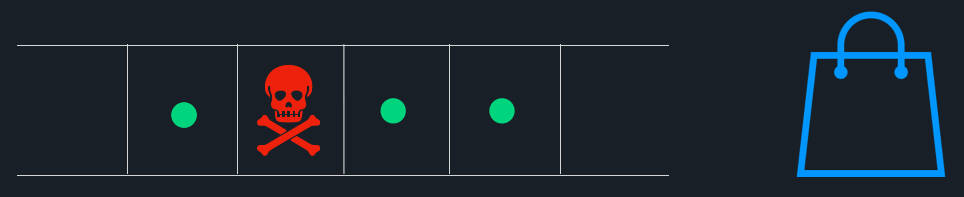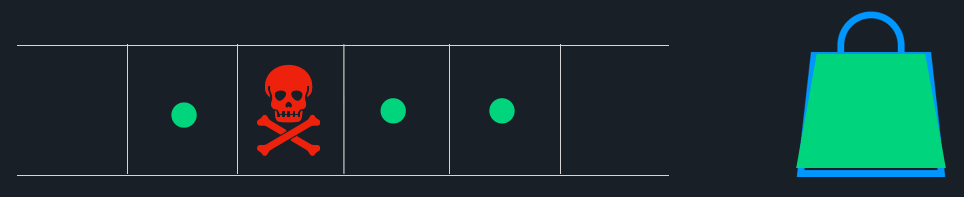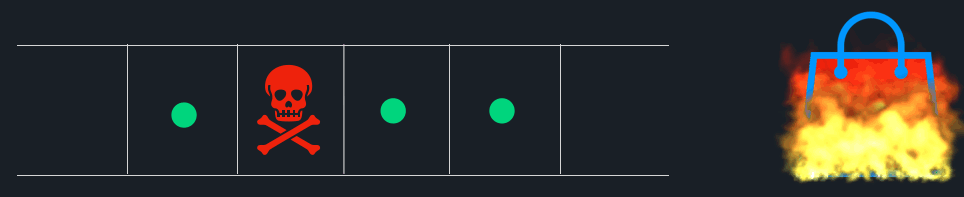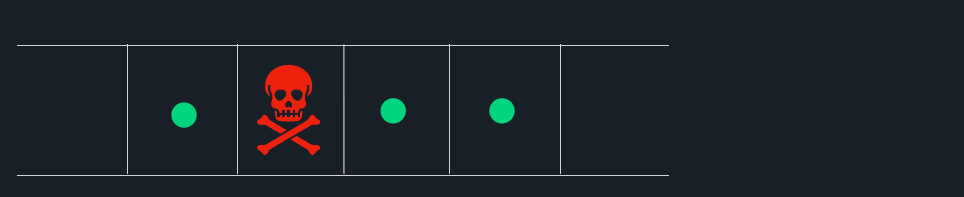
To better understand how poison pills cause HoLB, imagine an online vendor tracking orders on a website. Each order is produced to an orders topic. A consumer application is subscribed to this topic and needs to process each message so that a confirmation email for orders can be sent to customers.
The consumer application expects to receive a message that contains an integer for the product_id field, but instead, it receives a message with no value for that field. With no mechanism to deal with this poison pill, processing halts. This will stop all orders behind the message in question even though they could be processed without problems.
Non-Uniform Consumer Latency
Slow messages can cause non-uniform consumer latency, where a consumer takes an unusually long time to process a message. For instance, suppose a consumer application makes a call to one of many external services based on the contents of a message. If one of these external services is sluggish, a message's processing time will be unusually slow. Messages in the queue that don’t rely on the delayed external service will also experience an increase in processing latency.
HoLB Due to Non-Uniform Consumer Latency
To illustrate how non-uniform consumer latency causes HoLB, imagine a consumer application that is subscribed to the greenAndOrangeMessages topic. It receives the messages and routes them to one of two external services based on their color.
- If the message is green, it is sent to the green external service, called Green Service.
- If the message is orange, it is sent to the orange external service, called Orange Service.
As the consumer is pulling messages, there’s a sudden spike in latency in the response from Orange Service. When the consumer calls Orange Service while processing the orange message, the lack of response blocks the processing of all messages behind it.

Although all the messages behind the orange message are green, they cannot be processed by the consumer, even though Green Service is functioning normally. Here, non-uniform consumer latency slows down the entire partition and causes HoLB.
The consequences of HoLB in a message queue can range from disruptive, such as slow performance, to fatal - potential crashes. An obvious solution to these issues might be simply dropping messages; however, in many cases, data loss is unacceptable. For our use case, an ideal solution would retain all messages.
Solution Requirements
Based on the problem space described, we determined the following requirements for a solution:
- It should be publicly available to consumer application developers.
- It should serve developers working in a polyglot microservices environment.
- It should prevent data loss (messages should never be dropped).
- It should integrate smoothly into existing architectures.
- It should be easily deployed regardless of the user’s cloud environment (if any).
Alternative Approaches
With the aforementioned requirements in mind, we extensively researched existing solutions and approaches to solving HoLB. The solutions we found ranged from built-in Kafka configurations to service models built to support large Kafka deployments.
Kafka Auto-Commit
By default, the Kafka consumer library sends commits back to Kafka every 5 seconds, regardless of whether a message has been successfully processed. Where data loss is not an issue, auto-commit is a reasonable solution to HoLB. If a problematic message is encountered, the application can simply drop the message and move on. However, where data loss is unacceptable, this approach will not work.
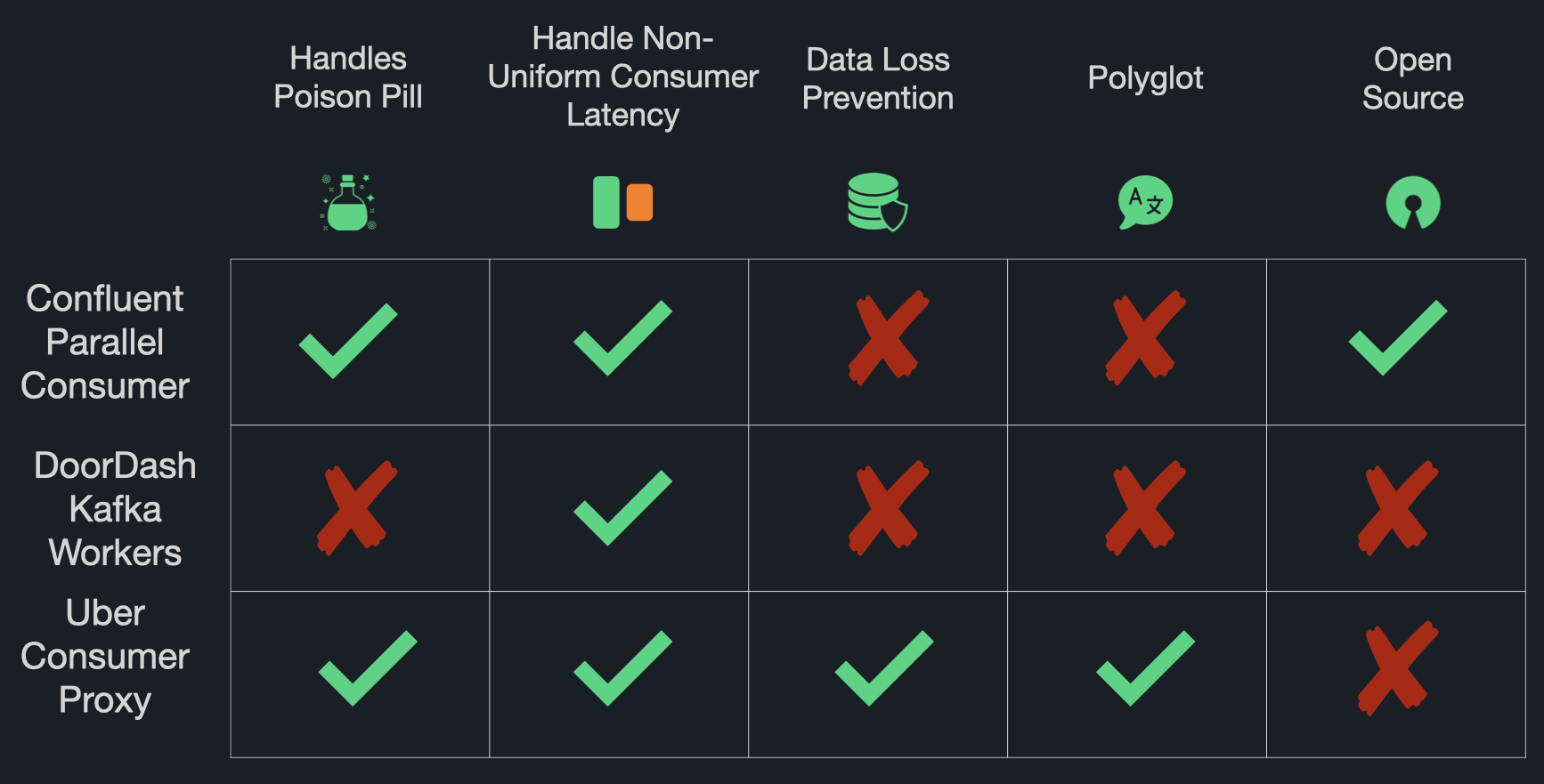
Confluent Parallel Consumer
Confluent Parallel Consumer (CPC) is a Java Kafka Consumer library that seemingly addresses HoLB by offering an increase in parallelism beyond partition count for a given topic [3]. It operates by processing messages in parallel using multiple threads on the consumer application’s host machine.
While CPC is an attractive solution, there were a few areas where it differed from our design requirements. The most obvious shortcoming for us was the fact that it's written in Java. In modern polyglot microservice environments, this presents a notable con - any developer wanting to utilize the advantages of CPC would need to rewrite their applications in Java.
Additionally, our requirements did not permit data loss; while setting up data loss prevention with CPC is feasible, we sought a solution that came with this functionality out of the box.
Kafka Workers (DoorDash)
DoorDash chose to leverage Kafka to help them achieve their goals of rapid throughput and low latency. Unfortunately, their use of Kafka introduced HoLB caused by non-uniform consumer latency.
The worker-based solution that Doordash implemented to address this problem consists of a single Kafka consumer instance per partition, called a "worker," which pipes messages into a local queue [4]. Processes called task-executors, within the "worker" instance, then retrieve the events from this queue and process them.
This solution allows events on a single partition to be processed by multiple task-executors in parallel. If a single message is slow to process, it doesn’t impact the processing time of other messages. Other available task-executors can read off the local queue and process messages even though a message at the head might be slow.
While this solution solves HoLB caused by non-uniform consumer latency, it did not fit our design requirements due to its lack of data loss prevention. According to DoorDash, if a worker crashes, messages within its local queue may be lost. As previously established, data loss prevention was a strict design requirement for us, making this approach a poor fit for our use case.
Consumer Proxy Model (Uber)
Uber sought to solve HoLB caused by non-uniform consumer latency and poison pills while ensuring at-least-once delivery since they deemed data loss intolerable.
Their solution, Consumer Proxy, solves HoLB by acting as a proxy between the Kafka cluster and multiple instances of the consumer application [5]. With this approach, messages are ingested and then processed in parallel by consumer instances. Consumer Proxy also uses a system of internal acknowledgments sent by consumer instances, indicating the successful processing of a message. Consumer Proxy only commits messages back to Kafka which have been successfully processed. If a message cannot be processed, a dead-letter queue is used to store it for later retrieval.
Uber’s Consumer Proxy is a feature-rich solution that seems to fulfill all of our requirements. It eliminated HoLB due to the two causes our team was concerned with while avoiding data loss. That being said, Consumer Proxy is an in-house solution that is not publicly available for consumer application developers.
Introducing Triage

Based on our research, none of the solutions fit all of our requirements – they either were not supported in multiple languages, failed to solve HoLB for both causes identified, or were not publicly available. We chose Uber's consumer proxy model as the basis for Triage because it solved both causes of HoLB and was language agnostic. As seen in the figure above, a Triage instance acts as a Kafka consumer proxy and passes messages to downstream consumer instances.
How Does Triage Work?
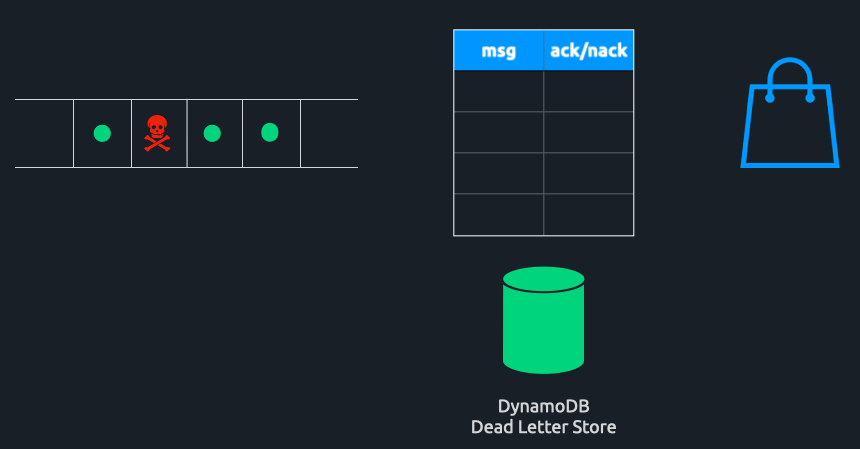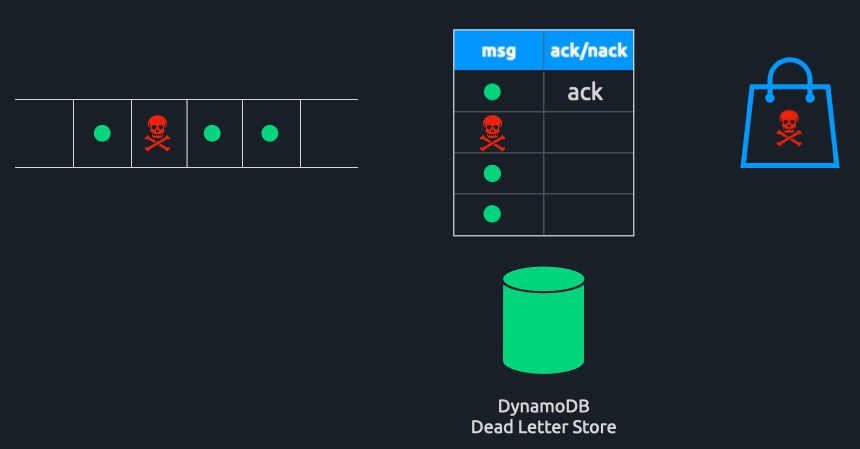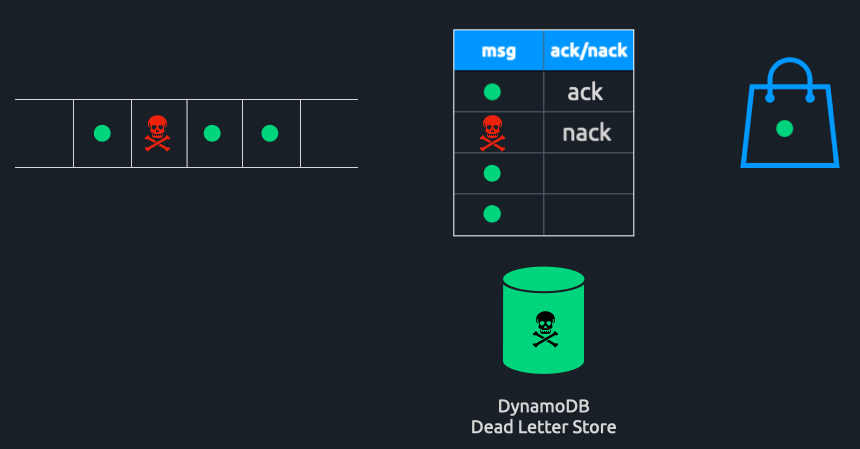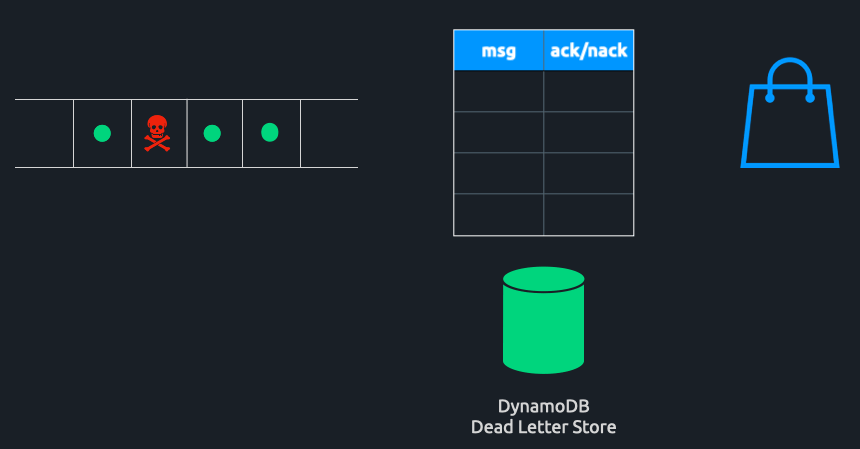
Triage will subscribe to a topic on the Kafka cluster and begin consuming messages. When a message is consumed, it is sent to an instance of a consumer application. This consumer instance will process the message and send back a status code that reflects whether or not a message has been successfully processed. Triage uses an internal system of acks and nacks (acknowledgments and negative acknowledgments) to identify healthy versus poison pill messages.
Internally, Triage uses a Commit Tracker to determine which messages have been successfully acknowledged and can be committed back to Kafka. Once it has done so, those records are deleted from the tracker. For messages that have been negatively acknowledged, Triage utilizes the dead-letter pattern to avoid data loss.
Triage Solves HoLB Caused By Poison Pills
When a poison pill is encountered, the consumer instance will send back a nack for that message. A nack directs Triage to deliver the message record in its entirety to a DynamoDB table. Here, it can be accessed at any point in the future for further analysis or work. The partition will not be blocked, and messages can continue to be consumed uninterrupted.
Triage Solves HoLB Caused by Non-Uniform Consumer Latency
With Triage, if a consumer instance takes an unusually long time to process a message, the partition remains unblocked. Messages can continue to be processed using other available consumer instances. Once the consumer instance finishes processing the slow message, it can continue processing messages.

How Can I Use Triage?
Deploying Triage
Triage can be deployed using our triage-cli command line tool, available as an NPM package. It offers a 2 step process that deploys Triage to AWS. You can read our step-by-step instructions here: Triage CLI.
Connecting to Triage
Consumer applications can connect to Triage using our thin client library, currently offered in Go. It handles authenticating with and connecting to Triage and provides an easy-to-use interface for developers to indicate whether a message has been processed successfully.
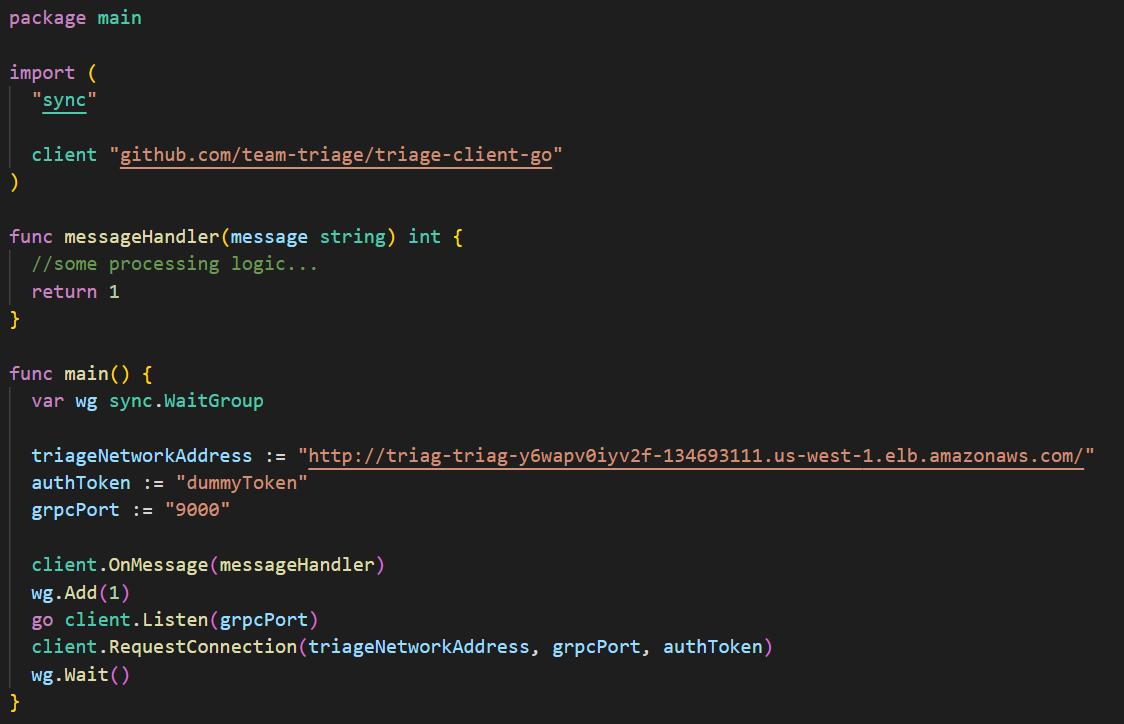
Triage Design Challenges
Based on our requirements for Triage, we encountered a few challenges. Below, we’ll present our reasoning behind the solutions we chose and how they allowed us to fulfill all of our solution requirements.
Polyglot Support
Challenge
We knew we wanted Triage to be language-agnostic – a consumer application should be able to connect to Triage, regardless of the language it’s written in. To do this, we had to consider whether Triage would exist as a service between Kafka and the consumer or as a client library on the consumer itself. We also needed to decide on a suitable network protocol.
Solution
By leveraging a service + thin client library implementation and gRPC code generation, we can build out support for consumer applications written in any language with relative ease.
Service vs. Client Library
On one hand, a client library offers simplicity of implementation and testing, as well as the advantage of not having to add any new pieces of infrastructure to a user’s system. We could also expect to get buy-in from developers with less pushback, as testing a client library with an existing system is more manageable than integrating a new service.
There were, however, some disadvantages with this approach. Our solution to addressing non-uniform consumer latency relies on parallel processing of a single partition. While, in theory, a client library could support multiple instances of a consumer application, a service implementation is more straightforward. Even if a client library were to be designed to dispatch messages to multiple consumer instances, it would begin to resemble a service implementation.
Another concern of ours was ease of maintainability. Within modern polyglot microservice environments, maintenance of client libraries written in multiple languages consumes a non-trivial amount of engineering hours. Changes in the Kafka version and the dependencies of the client libraries themselves could cause breaking changes that require time to resolve. We assumed that those hours could be better spent on core application logic.
Kafka can be difficult to work with. While the core concepts of Kafka are relatively straightforward to understand, in practice, interaction with a Kafka cluster involves a steep learning curve. There are over 40 configuration settings that a Kafka client can specify, making setting up an optimal or even functional consumer application difficult. Uber, for example, noted that their internal Kafka team was spending about half of their working hours troubleshooting for consumer application developers [6].
By centralizing the core functionality of Triage to a service running in the cloud and only utilizing a thin client library for connecting to Triage, support and maintenance become easier. Triage’s client library is simple – it makes an initial HTTP connection request with an authentication key provided by the developer and runs a gRPC server that listens for incoming messages. Implementing support in additional languages for this thin client library is straightforward, and much of the challenge around configuring a Kafka consumer is abstracted away from the developer.
Network Protocol
The next decision that we faced was choosing an appropriate network protocol for communication with consumer applications. HTTP was an obvious consideration both for its ubiquity and ease of implementation; however, after further research, we felt gRPC was the better option [10].
gRPC allows us to leverage the benefits of HTTP/2 over HTTP/1.1, specifically regarding the size of traffic we send and receive. HTTP/2 uses protocol buffers which are serialized and emitted as binaries to achieve higher compression than HTTP/1.1, which typically uses the de-facto standard of JSON. Higher compression means less data to send over the network and ultimately, faster throughput.
A counterpoint to the compression argument is the existence and growing popularity of JSON with gzip. Compression gains from protocol buffers compared to JSON with gzip are less impressive; however, we run into similar dependency pains mentioned in our discussion of service versus client library implementations. Each version of the thin client library we would potentially write must import its own language’s implementation of gzip.
gRPC also makes it easy to build out support for multiple languages via out of the box code generation. Using the same gRPC files we’ve used for Triage's Go client library, we can utilize a simple command-line tool to generate gRPC server and client implementations in all major programming languages.
Enabling Parallel Consumption
Challenge
Since Triage operates by dispatching messages to several consumer instances, we needed a way to send messages to, and receive responses from, them simultaneously. We knew that the language we chose would play a significant role in solving this challenge.
Solution
By creating dedicated Goroutines for each consumer instance and synchronizing them with the rest of Triage via channels, we enable parallel consumption of a single Kafka partition.
Language
We chose Go for the relative simplicity of implementing concurrency via Goroutines and the ease of synchronization and passing data across these Goroutines via channels.
Goroutines
Goroutines can be thought of as non-blocking function loops that can run concurrently with other functions [11]. The resource overhead of creating and running a Goroutine is negligible, so it’s not uncommon to see programs with thousands of Goroutines. This sort of multithreaded behavior is easy to use with Go, as a generic function can be turned into a Goroutine by simply prepending its invocation with the keyword go. Each major component of Triage exists as a Goroutine, which often relies on other underlying Goroutines. Channels are used extensively to pass data between these components and achieve synchronization where needed.
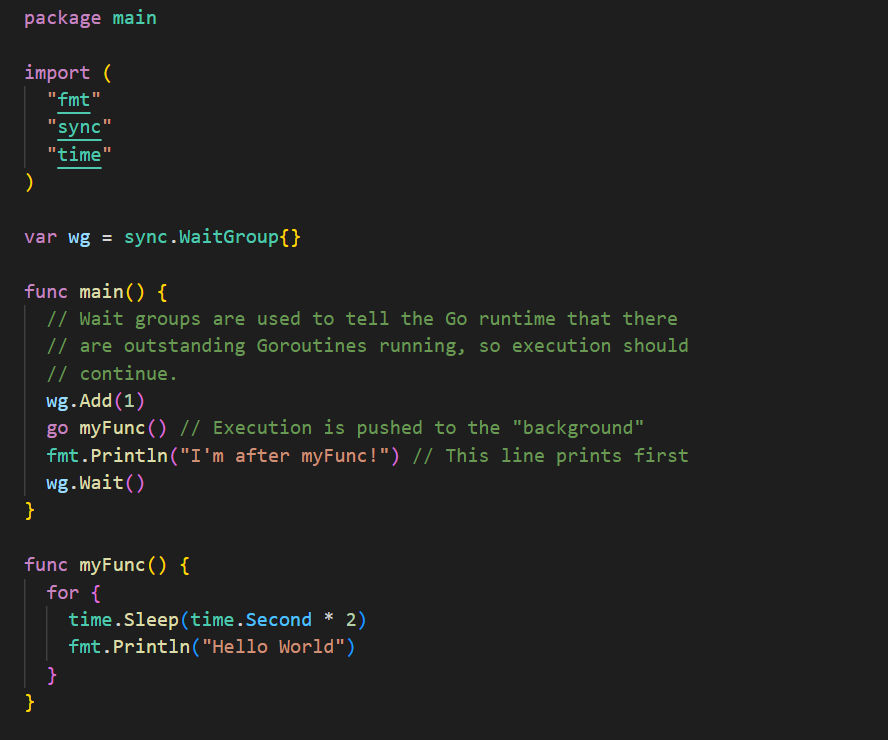
In the figure below, myFunc()'s execution will block execution of the print statement "I'm after myFunc!"
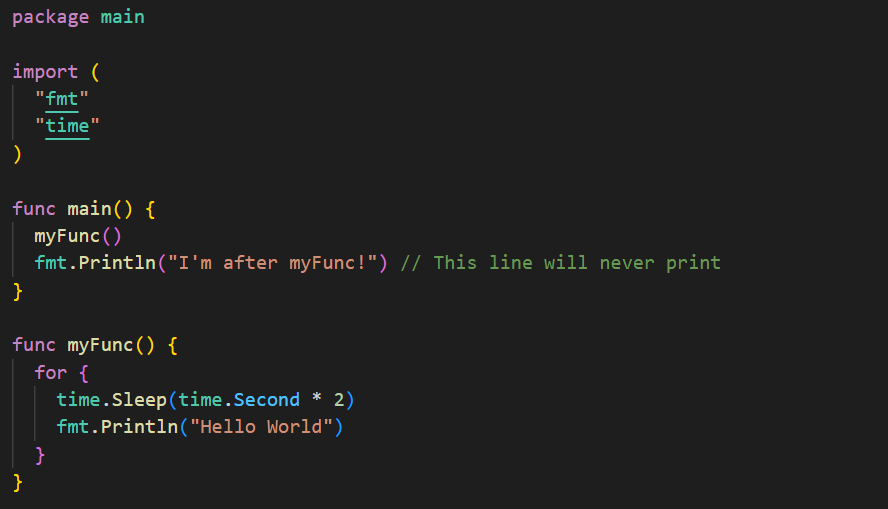
Conversely, the invocation of myFunc() below is prepended with the go keyword. It will now execute in the background, as a Goroutine, allowing the execution of the print statement.
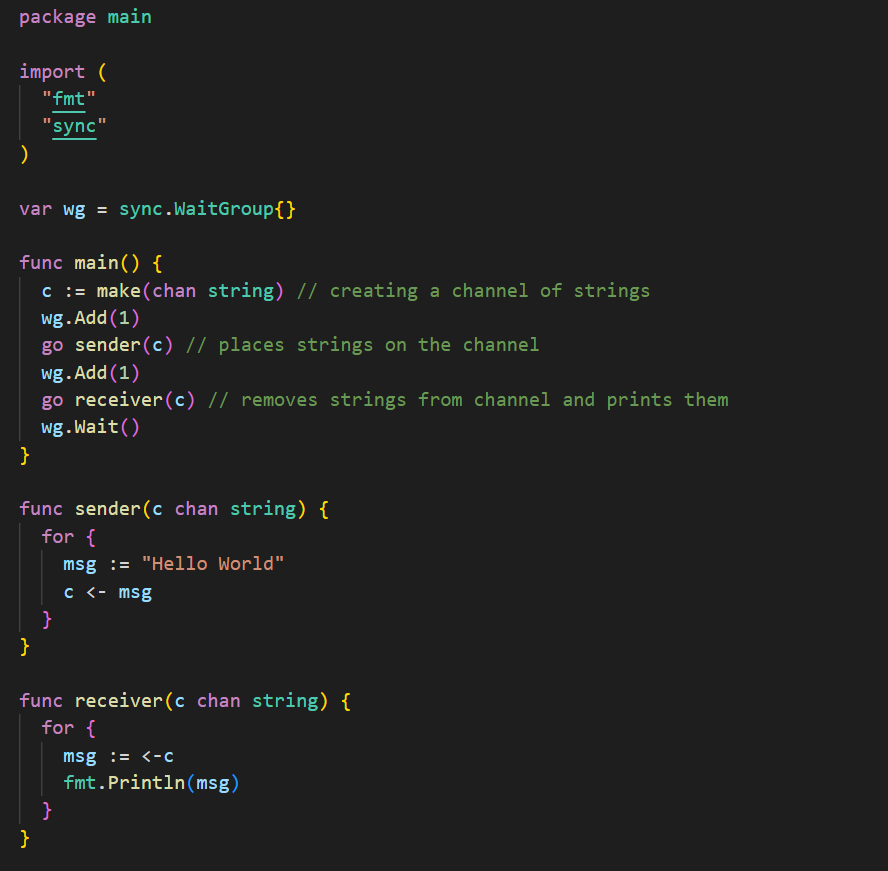
Channels
Channels in Go are queue-like data structures that facilitate communication across processes within a Go application. Channels support passing both primitives and structs. We can think of a function that writes a given value to a channel as a “sender” and a function that reads said value off of the channel as a “receiver.” When a sender attempts to write a message but there is no receiver attempting to pull a message off of the channel, code execution is blocked until a receiver is ready. Similarly, if a receiver attempts to read a message off of the channel when there is no sender, code execution is blocked until a sender writes a message.
Ease of Deployment
Challenge
We wanted to make sure that deploying Triage was as simple as possible for consumer application developers. Our goal was for setup, deployment, and teardown to be painless.
Solution
By taking advantage of the AWS Cloud Development Kit (CDK) in conjunction with AWS Fargate on Elastic Container Service (ECS), we were able to create an automated deployment script that interacts with our command line tool, triage-cli. This allows users to deploy a failure-resistant Fargate service to AWS in just a few easy steps.
AWS Fargate on ECS
We chose AWS for its wide geographic distribution, general industry familiarity, and support for containerized deployments.
AWS offers services in virtually every region of the world, meaning that developers looking to use Triage can deploy anywhere. We selected Fargate as the deployment strategy for Triage containers, removing the overhead of provisioning and managing individual virtual private server instances. Instead, we could concern ourselves with relatively simple ECS task and service definitions.
In our case, we define a task as a single container running Triage. Our service definition is a collection of these tasks, with the number of tasks being equal to the number of partitions for a given topic. This service definition is vital to how we guard against failure - if a Triage container were to crash, it would be scrapped and another would immediately be provisioned automatically.
Using Fargate doesn’t mean that we sacrifice any of the benefits that come with ECS since Fargate exists on top of ECS. Health checks and logs, as well as all of the infrastructure created during the deployment, are available to and owned by a user, since Triage deploys using the AWS account logged into the AWS CLI.
Automated deployment is enabled by CDK. Manually deploying Triage would require an understanding of cloud-based networking that would increase technical overhead. Amazon’s CDK abstracts that away – instead of having to set up the dozens of individual entities that must be provisioned and interconnected for a working cloud deployment, we were able to use ready-made templates provided by CDK for a straightforward deployment script.
triage-cli
We created triage-cli to interact with the deployment script created with AWS CDK. This allows us to interpolate user-specific configuration details into the script and deploy using just two commands – triage init and triage deploy.
Implementation
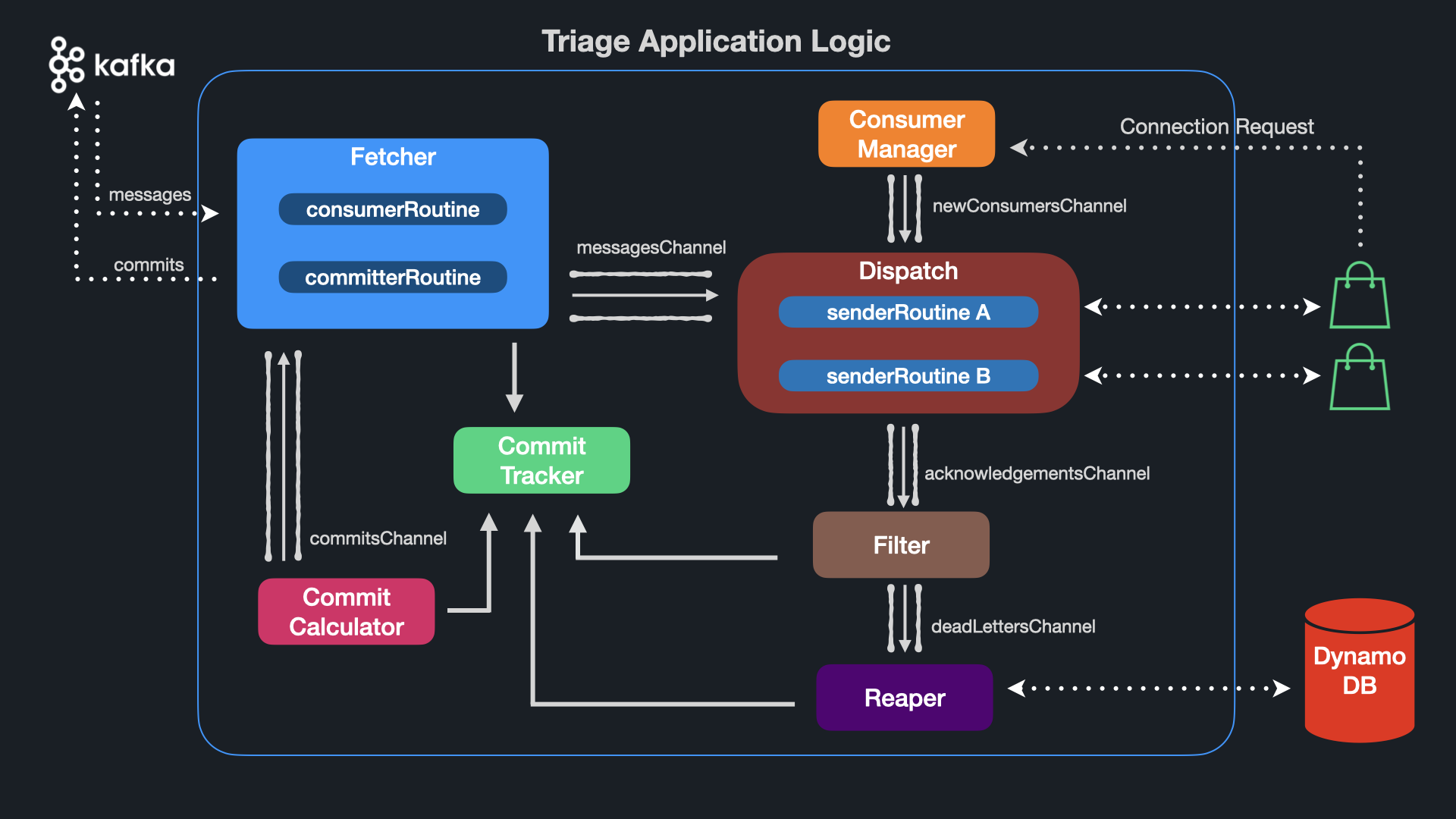
Having found solutions to our design challenges, our next step in developing Triage was implementation. In this section, we will discuss the components that make up the application logic of a Triage container, as well as provide a brief overview of how our thin client library interacts with it. We will address implementation with the following subsections:
- Message Flow - How Triage pulls messages from Kafka and sends them to consumers
- Consumer Instances - How a consumer instance receives messages from Triage and responds
- Handling Acks/Nacks - How Triage handles these responses
- Commits - How Triage handles commits
Message Flow
We will start by describing the flow of messages from Kafka, through Triage, to downstream consumer instances.
Fetcher
The Fetcher component is an instance of a Kafka consumer – it periodically polls Kafka for messages. It then writes these messages to the Commit Tracker component and sends them to the messages channel. We will discuss the Commit Tracker in a later section - for now, it is sufficient to know that a copy of a message ingested by Triage is stored in a hashmap, and a reference to this message is sent over the messages channel.
Consumer Manager
At this point in the flow, messages from Kafka are sitting in the messages channel and are ready to be processed. The Consumer Manager component runs a simple HTTP server that listens for incoming requests from consumer instances. After authenticating a request, the Consumer Manager parses the consumer instance’s network address and writes it to the newConsumers channel.
To recap, we now have messages from Kafka in a messages channel and network addresses to send them to in a newConsumers channel.
Dispatch
Triage’s Dispatch component is responsible for getting messages from within Triage to the consumer instances. We can think of Dispatch as a looping function that waits for network addresses on the newConsumers channel. When it receives a network address, it uses it to instantiate a gRPC client – think of this as a simple agent to make network calls. When this client is created, a connection is established between the client and the consumer at the network address.
senderRoutine
Dispatch then calls a function called senderRoutine, passing it the gRPC client as a parameter. senderRoutine is invoked as a Goroutine, ensuring that when Dispatch loops and listens for the next network address, senderRoutine continues to run in the background.
senderRoutine is essentially a for loop. First, a message is pulled off of the messages channel. The gRPC client passed to senderRoutine is then used to send this message over the network to the consumer instance. The senderRoutine now waits for a response.
Consumer Instances
We will now discuss how consumer instances receive messages from, and send responses to, Triage.
Consumer applications interact with Triage using the Triage Client. This client library is responsible for the following:
- Providing a convenience method to send an HTTP request to Triage
- Accepting a message handler
- Running a gRPC Server
We have already covered the HTTP request – we will now examine message handlers and gRPC servers.
Message Handler
Developers first pass the client library a message handler function – the message handler should have a Kafka message as a parameter, process the message, and return either a positive or negative integer based on the outcome of the processing. This integer is how consumer application developers can indicate whether a message has or has not been successfully processed.
gRPC Server
When the consumer application is started, it runs a gRPC server that listens on a dedicated port. When the server receives a message from Triage, it invokes the message handler, with the message as an argument. If the message handler returns a positive integer, it indicates that the message was successfully processed, and an ack is sent back to Triage. If the handler returns a negative integer, it indicates that the message was not processed successfully, and a nack is sent to Triage.
Handling Acks/Nacks
So far, we have covered how messages get from Kafka, through Triage, and to consumer instances. We then explained how Triage’s client library manages receiving these messages and sending responses. We will now cover how Triage handles these responses.
senderRoutine
As discussed in the message flow section, after sending a message to a consumer instance, senderRoutine waits for a response. When a response is received, senderRoutine creates an acknowledgment struct. The struct has two fields - Status and Message. The Status field indicates either a positive or negative acknowledgment. If the response was a nack, a reference to the message is saved under the Message field of the struct. For acked messages, the Message field can be nil. Finally, before looping to send another message, senderRoutine places the struct on the acknowledgments channel.
Filter
A component called Filter listens on the acknowledgments channel. It pulls acknowledgment structs off the channel and performs one of two actions based on whether the struct represents an ack or a nack. For acks, Filter immediately updates the Commit Tracker’s hashmap. We will discuss the Commit Tracker’s hashmap in the next section - for now, it is enough to know that an ack means we can mark the entry representing the message in the hashmap as acknowledged.
For nacks, however, the hashmap cannot be updated immediately - we have a bad message and need to ensure it is stored somewhere before moving on. Filter places this negative acknowledgment in the deadLetters channel.
Reaper
A component called Reaper listens on this deadLetters channel. It makes an API call to DynamoDB, attempting to write the faulty message to a table. Once confirmation is received from DynamoDB that the write was successful, the entry representing the message in Commit Tracker’s hashmap can be marked as acknowledged.
At this point, we have covered how messages get from Kafka, through Triage, to consumer instances. We have also covered how consumer instances process these messages, send responses back to Triage, and how Triage handles these responses.
Commits
We will now cover the Commit Tracker component and how it allows us to manage commits back to Kafka effectively.
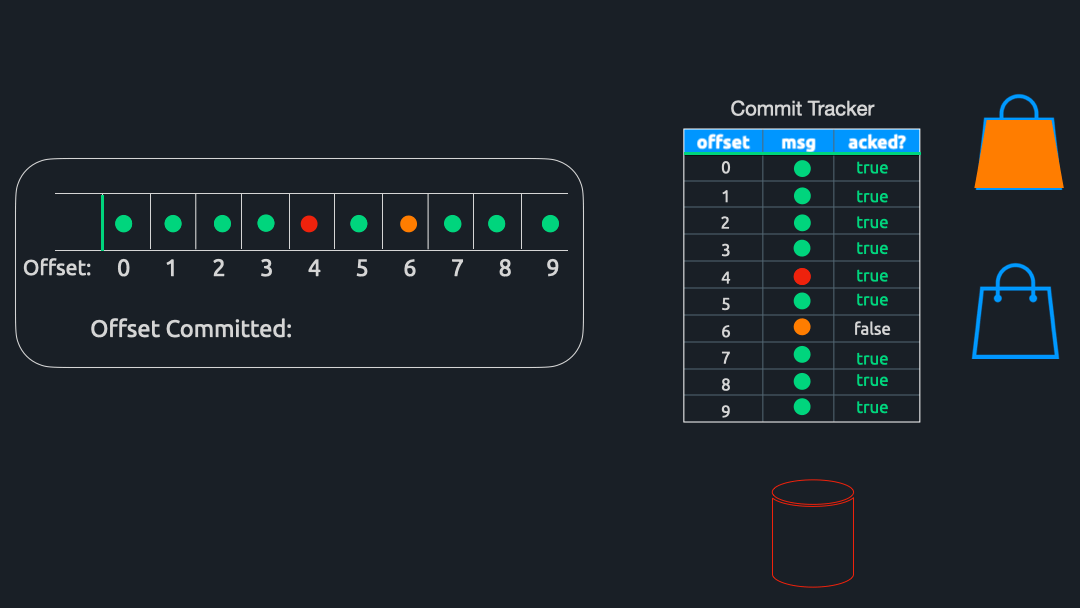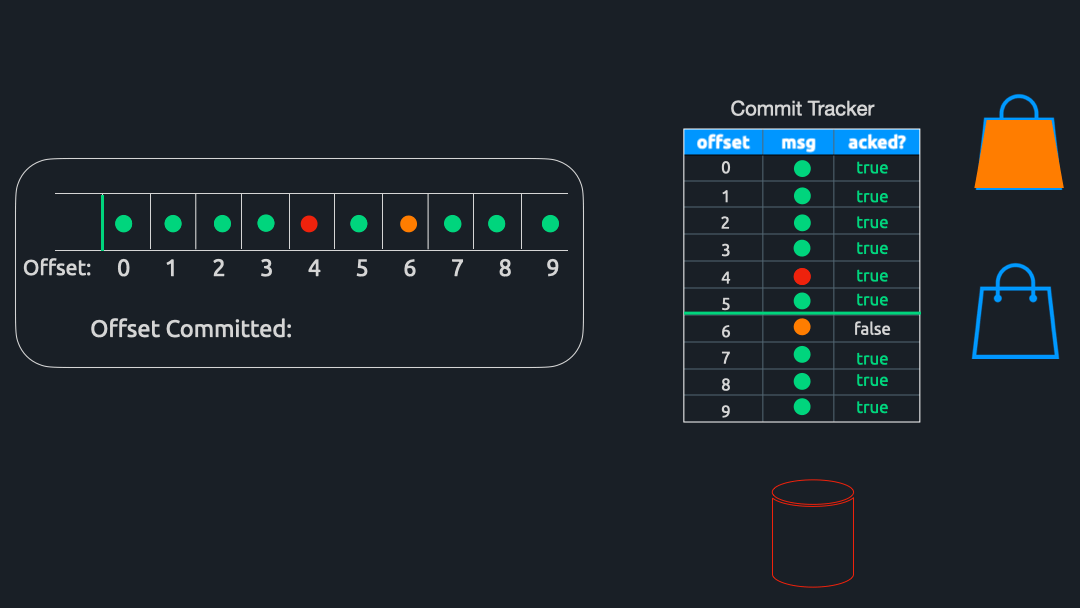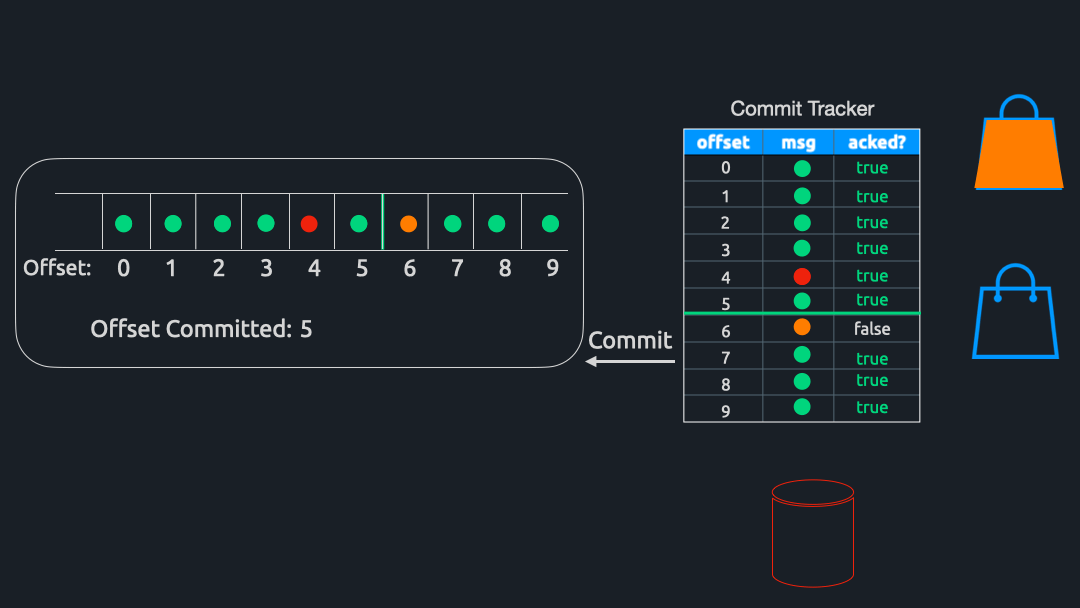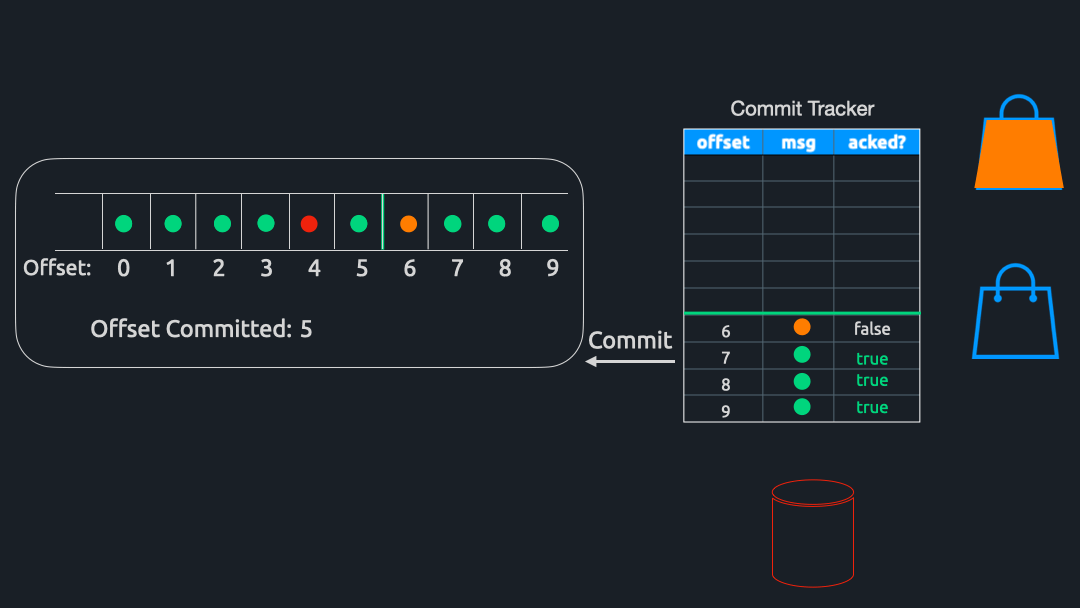
Commit Hashmap
As discussed in the message flow section, as messages are ingested by Triage, we store a reference to them in a hashmap. The hashmap’s keys are the offsets of the messages, and the values are a custom struct called CommitStore. The CommitStore struct has two fields - Message and Value . The Message field stores a reference to a specific Kafka message; the Value field stores whether or not Triage has received a response for this message.
Previously, we mentioned that the Filter and Reaper components marked messages in the hashmap as acknowledged. More specifically, they were updating the Value field. Because messages that are nacked are stored in DynamoDB for processing at a later time, we can think of them as “processed,” at least with respect to calculating which offset to commit back to Kafka.
Commit Calculator
To calculate which offset to commit, a component called CommitCalculator periodically runs in the background. To be efficient with our commits, we want to commit the highest offset possible since Kafka will implicitly commit all messages below our committed offset. For example, if there are 100 messages in a partition and we commit offset 50, Kafka will consider offsets 0-49 as “committed.”
Extending this example, let us assume that these 100 messages are currently stored in the hashmap. If we have received acknowledgments for offsets 0 through 48 – and offset 50 – but have not yet received an acknowledgment for offset 49, we cannot commit offset 50 since that would imply that 49 has been successfully processed. Instead, we can only commit offset 48 and have to wait for the acknowledgment for 49 before committing 50.
In other words, Commit Tracker commits the greatest offset for which all previous messages have also been acknowledged. Once this offset is determined, Triage sends a commit back to the Kafka cluster and awaits confirmation that the commit was successful. Finally, all entries up to and including the offset of the message just committed are removed from Commit Tracker’s hashmap.
Having covered commits, we have arrived at the end of a message’s life cycle within a system using Triage.
Future Work
Below are the improvements we would like to implement in the future.
Language Support for the Triage Client Library
It would be beneficial to have our client library written in other widely used languages, such as JavaScript and Ruby. This would enable more developers to use Triage and cement our decision to use a service + thin client implementation.
Cause of Failure Field
Giving developers the ability to add a reason for failed messages would help them identify and analyze errors. Developers could supply a custom field on the nack sent to Triage. We would store this field with the message record in the DynamoDB table.
Notifications for Poison Pills
We believe developers could benefit from notifications when poison pills are written to DynamoDB. Having these notifications integrated with a platform like Slack could serve as an alarm to respond rapidly. We think this is a relatively easy feature to implement and is likely our next step.
Our Team




References
1. https://dzone.com/articles/new-research-shows-63-percent-of-enterprises-are-a
3. https://www.confluent.io/blog/introducing-confluent-parallel-message-processing-client/
4. https://doordash.engineering/2020/09/03/eliminating-task-processing-outages-with-kafka/
5. https://www.uber.com/en-CA/blog/kafka-async-queuing-with-consumer-proxy/
6. https://videos.confluent.io/watch/Jw7M7MpKVE5sS4hu2dWGvU
7. https://www.arxiv-vanity.com/papers/2104.00087/
8. https://en.wikipedia.org/wiki/Head-of-line_blocking
9. https://www.youtube.com/watch?v=j2TeOyjoAZc
10. https://learn.microsoft.com/en-us/aspnet/core/grpc/comparison?view=aspnetcore-7.0
11. https://softwareengineeringdaily.com/2021/03/03/why-we-switched-from-python-to-go/